Continuous Queries
8 minute read
Continuous Queries Continuous Query A query that runs continuously, maintaining an always-current result set as data changes. Learn more are the heart of Drasi. They define which changes matter to your solution and what data to distribute when those changes occur. Unlike traditional queries that run once and return static results, Continuous Queries run perpetually, maintaining an up-to-date result set Result Set The current output of a Continuous Query, updated automatically as data changes. Learn more and notifying you precisely when that result set changes.
Sources Source A connection to an external system that Drasi monitors for data changes. Learn more feed Source Change Events Source Change Event A notification from a Source describing a data change (insert, update, or delete). Learn more to Continuous Queries, which process them and notify Reactions Reaction A component that receives query result changes and takes action on them. Learn more of any additions, updates, or deletions to the query result caused by the Source Change Event.
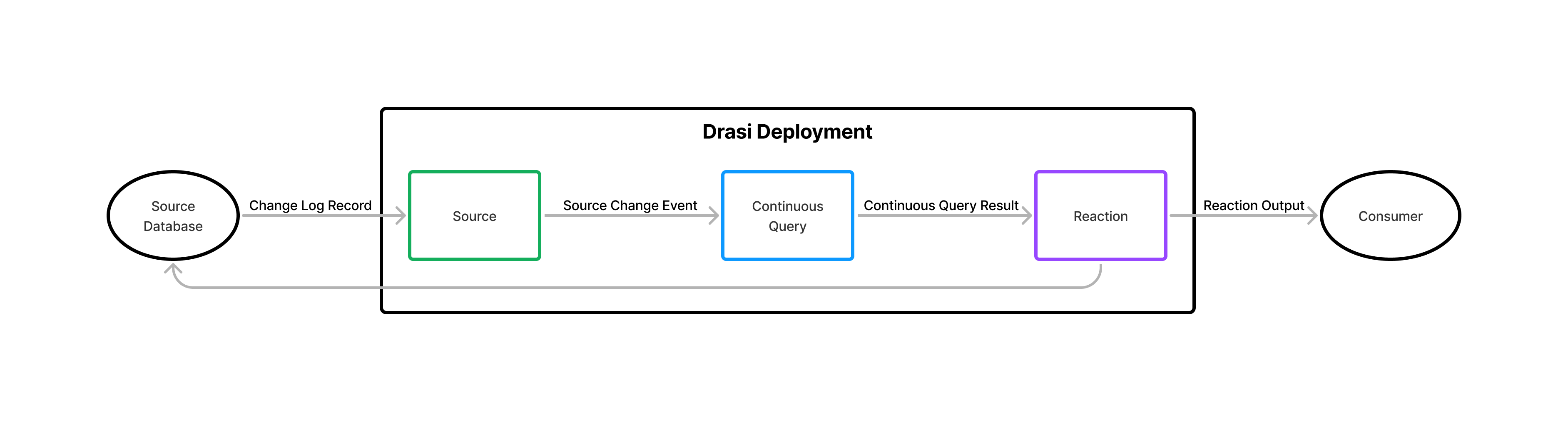
How Continuous Queries Work
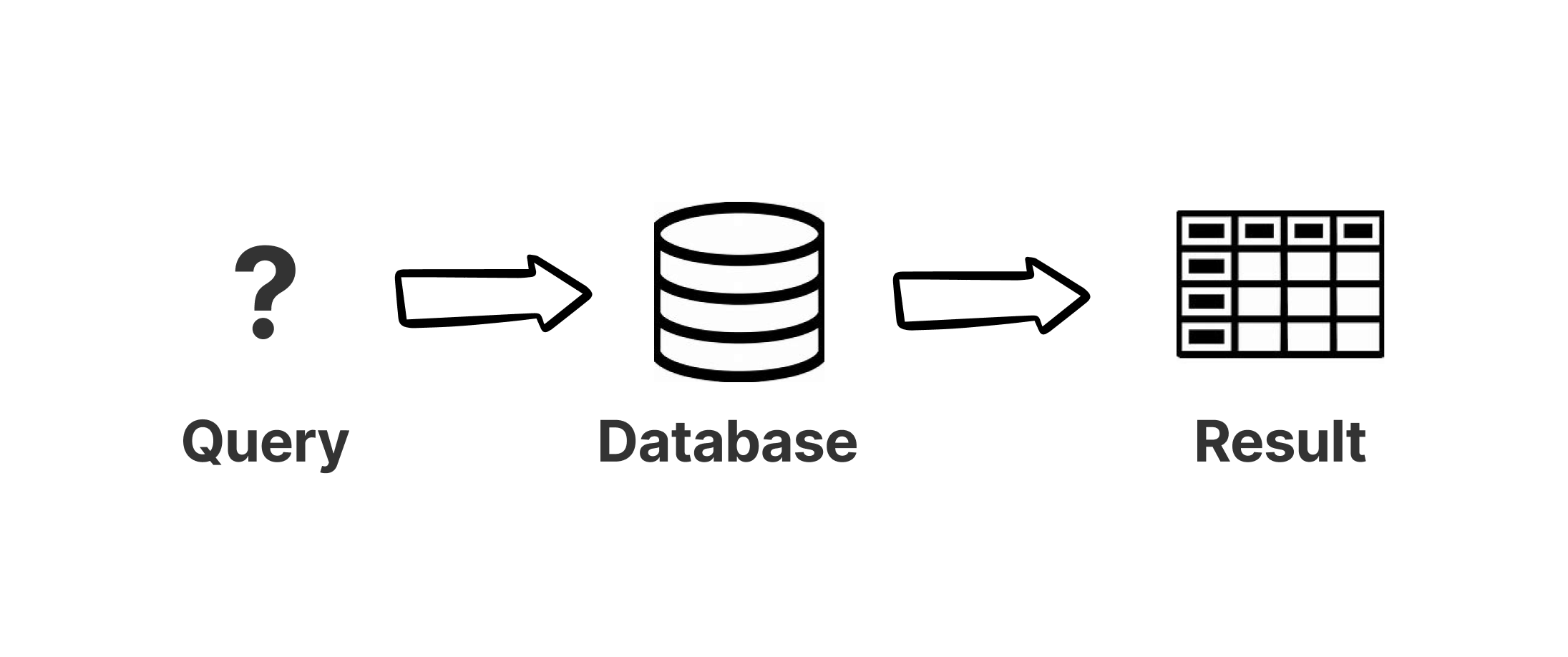
To understand what makes Continuous Queries unique, contrast them with the instantaneous queries Instantaneous Query A conventional query that returns a static snapshot of data at a moment in time. Learn more developers typically run against databases.
When you execute an instantaneous query, you run the query against the database at a point in time. The database calculates the results and returns them. While you work with those results, you have a static snapshot–you are unaware of any changes that happen after you ran the query. If you run the same query periodically, the results might differ each time due to changes made by other processes. But to understand what changed, you would need to compare the most recent result with the previous result.
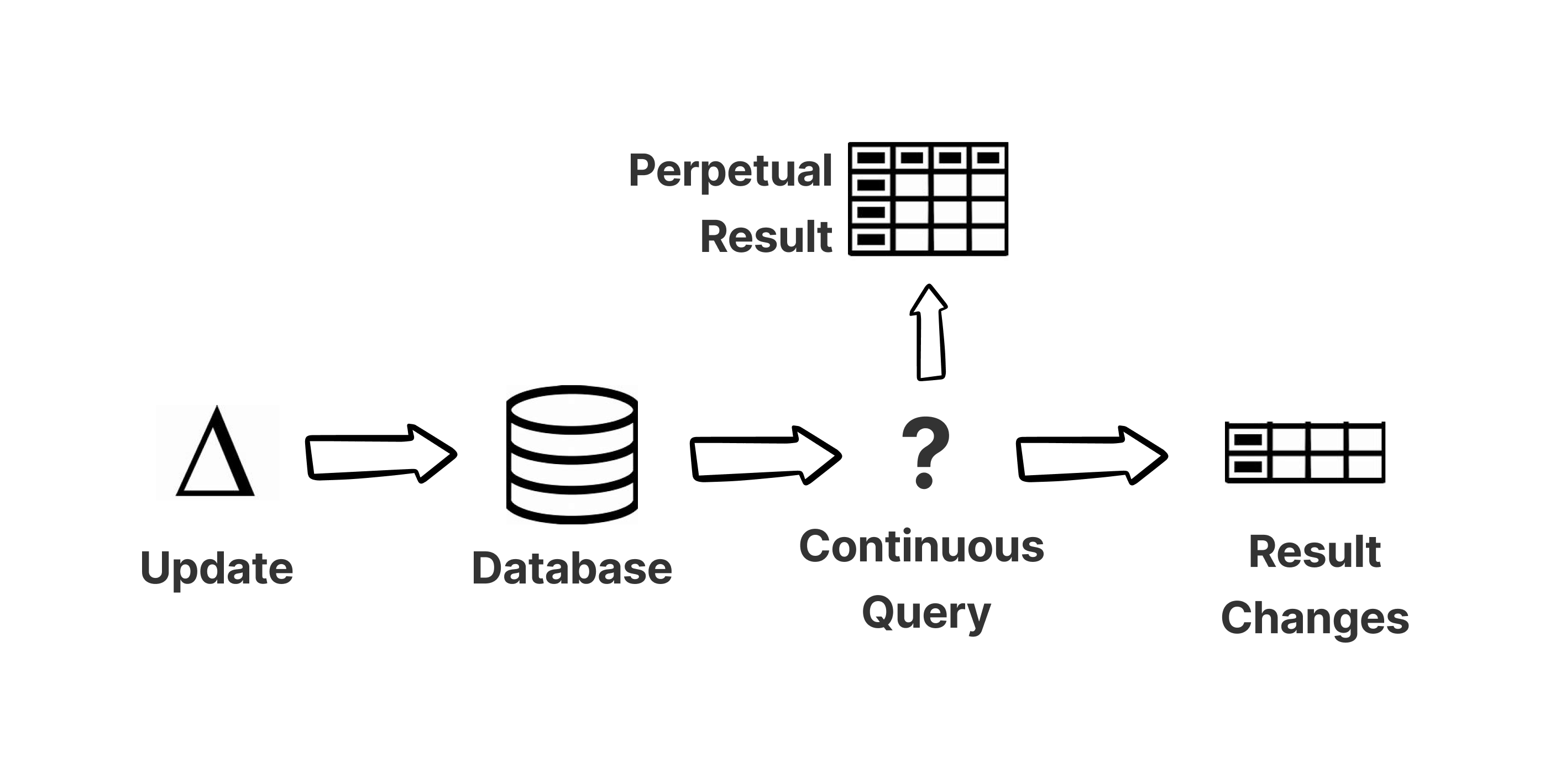
Continuous Queries, once started, continue to run until stopped. While running, they maintain a perpetually accurate query result, incorporating any changes made to the source database as they occur. Not only can you request the query result at any point in time, but as changes occur, the Continuous Query determines exactly which result elements have been added, updated, and deleted, and distributes a precise description of the changes to all Reactions that have subscribed to it.
Query Languages
Continuous Queries are written using either openCypher openCypher A declarative graph query language used to write Drasi Continuous Queries. Learn more or Graph Query Language GQL An ISO-standard graph query language supported by Drasi for Continuous Queries. Learn more (GQL). Both are declarative graph query languages that allow you to:
- Describe in a single query expression which changes you want to detect and what data notifications should contain
- Express rich query logic that considers both property values and relationships between data
- Create queries that span data across multiple Sources without complex join syntax, even when there is no natural connection between data in the source systems
Choosing a Query Language
| Language | Best For | Key Features |
|---|---|---|
| openCypher | Neo4j users, ASCII-art graph patterns | Widely adopted, extensive documentation, familiar syntax |
| GQL | ISO standard compliance, modern graph queries | ISO standardized |
Both languages share similar pattern-matching syntax using round brackets for nodes and arrows for relationships. For complete syntax reference, see Query Language Reference.
Example: Incident Alerts
Imagine an Incident Alerting Service that notifies managers when employees in their team are at risk due to dangerous incidents in their location (fires, storms, civil unrest, etc.). Assume the source data is a property graph of nodes (rectangles) and relations (lines) as shown:
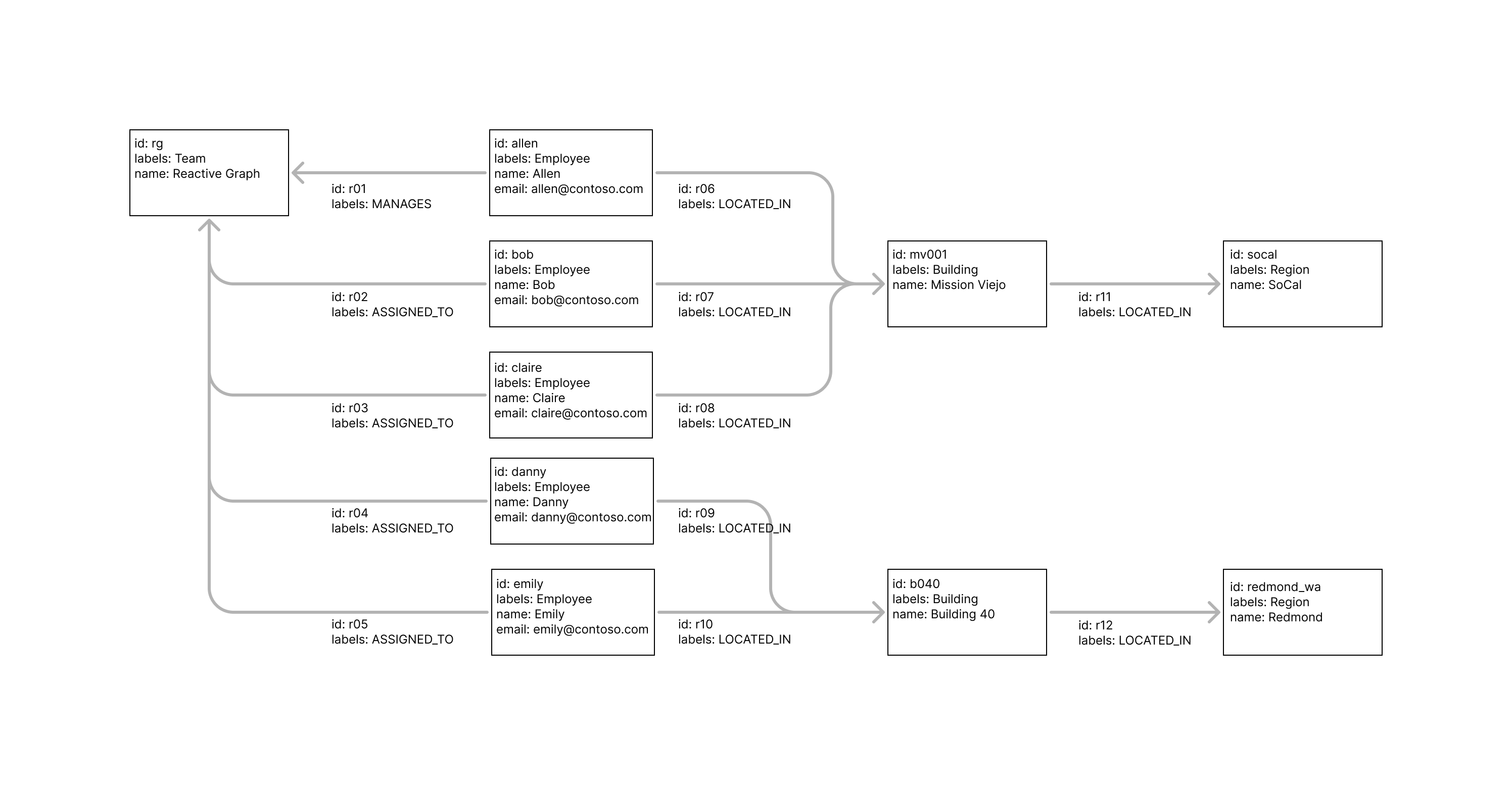
Using Drasi, you can write a query to identify each employee at risk.
openCypher:
MATCH
(e:Employee)-[:ASSIGNED_TO]->(t:Team),
(m:Employee)-[:MANAGES]->(t:Team),
(e:Employee)-[:LOCATED_IN]->(:Building)-[:LOCATED_IN]->(r:Region),
(i:Incident {type:'environmental'})-[:OCCURS_IN]->(r:Region)
WHERE
elementId(e) <> elementId(m) AND i.severity IN ['critical', 'extreme'] AND i.endTimeMs IS NULL
RETURN
m.name AS ManagerName, m.email AS ManagerEmail,
e.name AS EmployeeName, e.email AS EmployeeEmail,
r.name AS RegionName,
elementId(i) AS IncidentId, i.severity AS IncidentSeverity, i.description AS IncidentDescription
GQL:
MATCH
(e:Employee)-[:ASSIGNED_TO]->(t:Team),
(m:Employee)-[:MANAGES]->(t:Team),
(e:Employee)-[:LOCATED_IN]->(:Building)-[:LOCATED_IN]->(r:Region),
(i:Incident {type:'environmental'})-[:OCCURS_IN]->(r:Region)
WHERE
element_id(e) <> element_id(m) AND i.severity IN ['critical', 'extreme'] AND i.endTimeMs IS NULL
RETURN
m.name AS ManagerName, m.email AS ManagerEmail,
e.name AS EmployeeName, e.email AS EmployeeEmail,
r.name AS RegionName,
element_id(i) AS IncidentId, i.severity AS IncidentSeverity, i.description AS IncidentDescription
The MATCH and WHERE clauses describe a pattern that identifies all Employees located in Buildings within Regions where there are active Incidents of type ’environmental’ with severity level ‘critical’ or ’extreme’. Any combination of correctly connected nodes with the required property values is included in the query result.
The RETURN clause generates output containing the name and email address of the at-risk employee and their manager, plus incident and region details. This defines the schema for results generated by the Continuous Query.
How Results Change Over Time
When the above Continuous Query first runs, there are no results because there are no Incidents in the data. But as soon as an extreme severity Forest Fire Incident in Southern California is added:
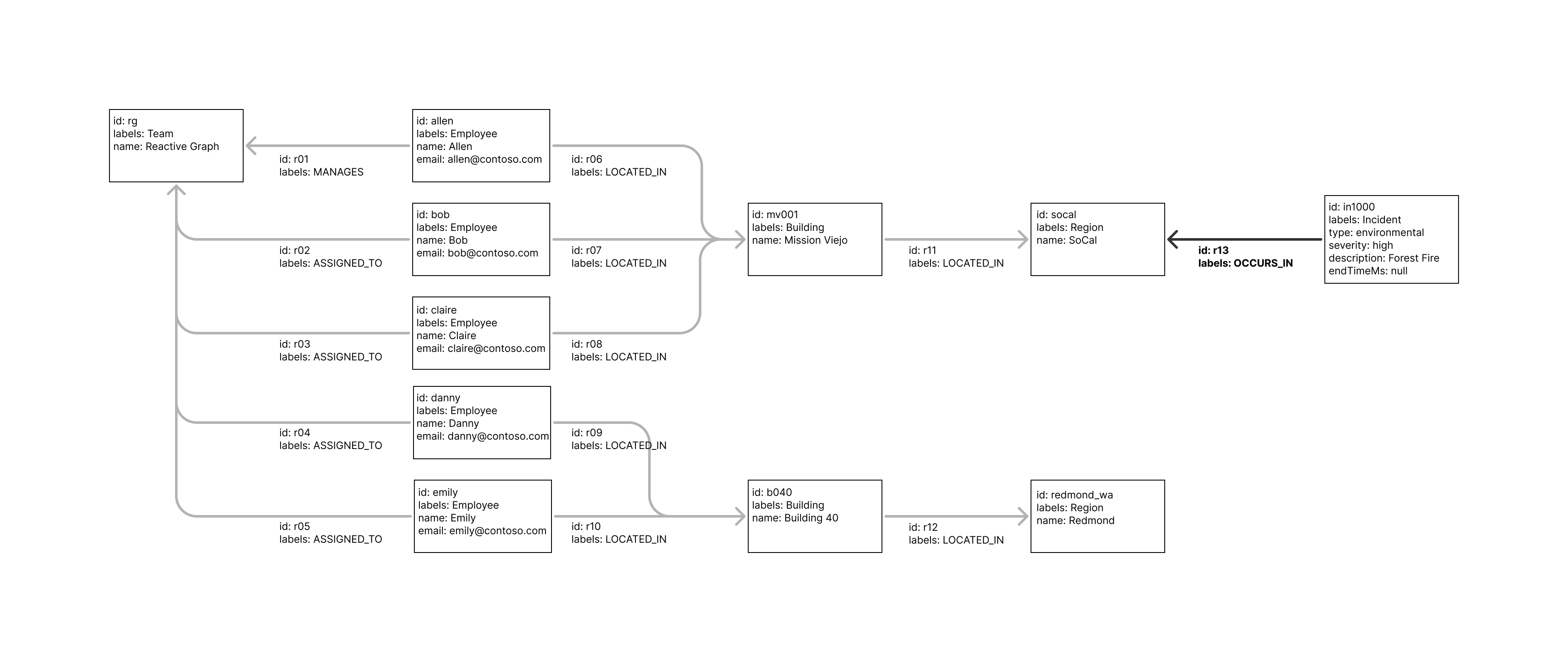
The query generates output showing that two records (for employees Bob and Claire) now meet the query criteria and have been added to the result:
{
"added": [
{ "ManagerName": "Allen", "ManagerEmail": "allen@contoso.com", "EmployeeName": "Bob", "EmployeeEmail": "bob@contoso.com", "RegionName": "Southern California", "IncidentId": "in1000", "IncidentSeverity": "extreme", "IncidentDescription": "Forest Fire" },
{ "ManagerName": "Allen", "ManagerEmail": "allen@contoso.com", "EmployeeName": "Claire", "EmployeeEmail": "claire@contoso.com", "RegionName": "Southern California", "IncidentId": "in1000", "IncidentSeverity": "extreme", "IncidentDescription": "Forest Fire" }
],
"updated": [],
"deleted": []
}
If Bob subsequently changes location, removing him from Southern California while the Forest Fire is still active, the Continuous Query generates output showing Bob’s record has been deleted from the result:
{
"added": [],
"updated": [],
"deleted": [
{ "ManagerName": "Allen", "ManagerEmail": "allen@contoso.com", "EmployeeName": "Bob", "EmployeeEmail": "bob@contoso.com", "RegionName": "Southern California", "IncidentId": "in1000", "IncidentSeverity": "extreme", "IncidentDescription": "Forest Fire" }
]
}
If the Forest Fire severity changes from ’extreme’ to ‘critical’, the Continuous Query generates output showing Claire’s result has been updated, including both before and after versions:
{
"added": [],
"updated": [
{
"before": { "ManagerName": "Allen", "ManagerEmail": "allen@contoso.com", "EmployeeName": "Claire", "EmployeeEmail": "claire@contoso.com", "RegionName": "Southern California", "IncidentId": "in1000", "IncidentSeverity": "extreme", "IncidentDescription": "Forest Fire" },
"after": { "ManagerName": "Allen", "ManagerEmail": "allen@contoso.com", "EmployeeName": "Claire", "EmployeeEmail": "claire@contoso.com", "RegionName": "Southern California", "IncidentId": "in1000", "IncidentSeverity": "critical", "IncidentDescription": "Forest Fire" }
}
],
"deleted": []
}
In some instances, a single source change can result in multiple changes to the query result i.e. multiple records can be added, updated, and deleted. In such cases, the Continuous Query generates a single result change notification containing all the changes, enabling subscribed Reactions to treat related changes atomically.
Key Configuration Concepts
Continuous Query configuration varies by Drasi product, but all products support these core concepts:
Source Subscriptions
Queries subscribe to one or more Sources to receive data via source subscriptions Source Subscription A configuration that connects a Continuous Query to one or more Sources. Learn more . Within each subscription, you can:
- Specify which node Node A data entity in the property graph model, representing a discrete object or concept. Learn more and relation Relationship A connection between two nodes in the property graph, representing how entities relate. Learn more labels the query expects from that Source
- Define middleware Middleware Custom processing logic applied to source changes before query evaluation. Learn more pipelines to transform incoming changes (see below)
Joins
When a query uses multiple Sources, joins Join A mapping that connects data from multiple Sources based on matching properties. Learn more define how elements from different Sources connect. This allows you to write unified graph queries that span multiple databases without complex join syntax complicating the query. These connections create synthetic joins Synthetic Join A relationship between nodes created by query joins rather than source data. Learn more between nodes from different sources.
Middleware
Middleware transforms and enriches incoming data changes before they reach the query. Common uses include unwinding arrays, transforming data shapes, and remapping labels. See Middleware for a conceptual overview and Middleware Reference for detailed specifications.
Query Lifecycle
When a new Continuous Query is started, it:
- Subscribes to its Sources, describing the types of changes it wants to receive
- Queries its Sources to load initial data for its query result (the bootstrap Bootstrap The process of loading initial data when a Continuous Query starts. Learn more process)
- Processes the stream of Source Change Events from its Sources, translating them into changes to its query result Result Change Event A notification from a Continuous Query describing changes to its result set. Learn more
The Continuous Query continues running until explicitly stopped or deleted, at which point any Reactions that depend on it stop receiving query result changes.
Dependency Impact
Drasi for Kubernetes does not currently enforce dependency integrity between Continuous Queries and Reactions, so plan your Continuous Query lifecycle carefully.
Configuring Continuous Queries
Query configuration varies by Drasi product. Each product provides its own approach for defining queries with source subscriptions, joins, and middleware.
To configure Continuous Queries for your deployment, see the product-specific guide:
- Drasi for Kubernetes Drasi for Kubernetes A scalable Data Change Processing platform running on Kubernetes clusters. Learn more Queries - Configure queries using Kubernetes resource manifests
For drasi-lib drasi-lib A Rust crate for building change-driven solutions with embedded Drasi capabilities. Learn more , queries are configured programmatically via the Rust API. See the drasi-lib documentation for details.
Feedback
Was this page helpful?
Glad to hear it! Please tell us what you found helpful.
Sorry to hear that. Please tell us how we can improve.